
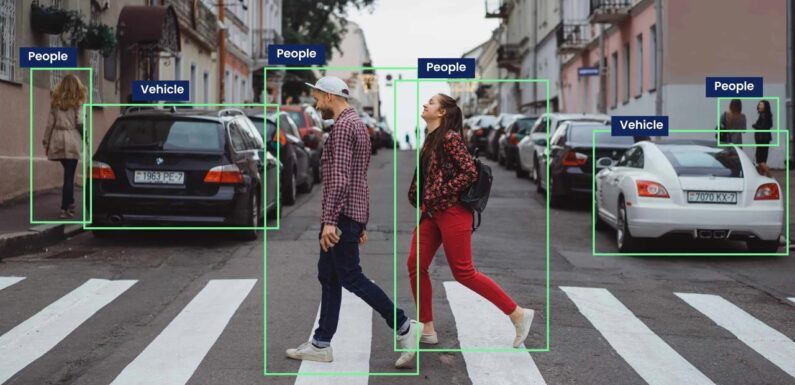
Video annotation services help AI models understand motion and context by labeling video data, improving accuracy and reliability across industries like autonomous vehicles, healthcare, surveillance, and robotics.
Artificial intelligence has evolved from recognizing static images to understanding dynamic, real-world motion. To teach AI systems how to interpret movement, context, and actions, they need more than still pictures they need well-labeled videos that capture how things change over time.
This is where video annotation services become a true game changer. By transforming raw video footage into meaningful training data, annotation empowers smarter, more context-aware AI models.
What Is Video Annotation?
Video annotation is the process of labeling objects, actions, and events within video footage so that machine learning models can learn from them. It captures both spatial and temporal details understanding what is happening and how it changes across time.
In simple terms, image annotation tells an AI what’s in a single picture, while video annotation for ML teaches it what, where, and when. This helps AI systems learn movement, timing, and context from continuous frames.
Types of Video Annotation
- Bounding Boxes: Rectangular boxes drawn around objects for detection and classification.
- Segmentation Masks or Polygons: Outline the exact shape of an object frame-by-frame for precise results.
- Keypoints and Pose Estimation: Mark specific joints or points on humans or objects to teach motion.
- Object Tracking: Label the same object across multiple frames to train models on movement.
- Event or Action Labeling: Tag actions like “car turning left” or “person waving” across sequences.
- 3D Cuboids and Trajectories: Used in autonomous driving or robotics to interpret depth and motion.
Why Video Annotation Differs from Image Annotation
Image annotation deals with single frames, while video annotation involves thousands of continuously changing ones. For instance, a 10-minute video at 30 fps generates about 18,000 frames a massive volume to label.
Beyond scale, time adds complexity. AI can analyze how objects enter, exit, and interact within frames essential for self-driving cars, robotics, and surveillance systems.
How Video Annotation Is Transforming AI
1. Enables Spatio-Temporal Learning
AI trained on annotated video understands both space (where things are) and time (how they move). This allows it to not only detect a pedestrian but also predict their next step making AI systems more intelligent and safer.
2. Improves Accuracy and Reliability
Video annotation reduces false positives and improves detection under variable lighting, motion, or occlusion. Combined human-AI labeling workflows can achieve up to 98% accuracy, greatly enhancing model reliability.
3. Provides Richer Context for Better Generalization
Annotated videos expose models to diverse real-world conditions changing light, angles, and behavior enabling them to perform better in unseen environments.
4. Powers Advanced AI Applications
- Autonomous Vehicles: Detect and predict cars, pedestrians, and cyclists.
- Security & Surveillance: Identify suspicious activity in real time.
- Healthcare: Analyze patient movement or surgical procedures.
- Retail & Sports Analytics: Track customer behavior or athlete performance.
- Manufacturing & Robotics: Detect defects or guide robotic motion.
5. Builds a Strategic Advantage
Organizations mastering video annotation in computer vision gain a competitive edge faster development cycles, better data quality, and smarter AI models.
Real-World Impact
- The global data annotation market is projected to grow from $0.8 billion in 2022 to $3.6 billion by 2027, driven mainly by video data.
- A 10-minute video produces around 18,000 frames for potential labeling.
- Hybrid automation can cut annotation time by 60% while maintaining accuracy.
Key Considerations for Effective Video Annotation
- Define Clear Objectives: Know what your model needs to learn: detect, recognize, or track.
- Choose the Right Technique: Use bounding boxes, keypoints, or segmentation as needed.
- Use Frame Sampling Wisely: Label every few frames to save time while maintaining quality.
- Maintain Quality Assurance: Consistent guidelines and reviewer checks ensure accuracy.
- Balance Automation & Human Expertise: Automation speeds up work; humans add precision.
- Ensure Privacy & Compliance: Protect sensitive data with secure storage and GDPR-ready workflows.
- Decide Between In-House or Outsourced Annotation: In-house offers control, while outsourcing video annotation services ensures scalability and cost efficiency.
Challenges and Solutions
| Challenge | Solution |
| High volume & cost | Use smart frame sampling and automation tools. |
| Consistency across frames | Apply object-tracking tools and strict QA. |
| Annotator fatigue | Rotate annotators and automate validation. |
| Tool limitations | Choose platforms optimized for long videos. |
| Bias in data | Diversify datasets and include edge cases. |
Future Trends in Video Annotation
- AI-Assisted Labeling: Pre-trained models will automate repetitive annotation.
- Real-Time Annotation: Live video and streaming applications will grow.
- Domain-Specific Workflows: Tailored solutions for healthcare, robotics, and AR/VR.
- Synthetic Data Generation: AI-created videos will supplement real datasets.
- Multimodal Training: Integration with audio and text for comprehensive AI learning.
Conclusion
Video annotation services are revolutionizing how AI systems learn, predict, and interact with the world. They enable models to understand motion, anticipate actions, and make informed decisions.
Organizations that invest in accurate, scalable, and advanced video annotation workflows or outsource video annotation services to experts will lead the next wave of AI innovation where machines don’t just see, but truly understand.
Now’s the time to level up your AI training pipeline:
- Evaluate your current annotation process.
- Run a pilot with sample videos.
- Create clear labeling guidelines.
- Combine automation with human oversight.
By doing so, you’ll unlock the full potential of video-based AI models smarter, safer, and ready for the real world.
